Facebook and Slack Outages Show That Visibility Is Mission Critical
- By Riverbed Technology
- 21-Dec-2021
In early October, two major outages related to DNS configuration changes affected the customer experience for the users of digital giants, Slack and Facebook. The failure of Facebook and its WhatsApp and Instagram services extended several hours and was catastrophic in nature–a routine maintenance change effectively took down Facebook’s global backbone. The company was forced to communicate with its own staff and customers via its rival service Twitter.
The Slack outage was less widescale, affecting only a proportion of corporate users for up to 24 hours, but it was also as the result of an erroneous maintenance command. In both incidents, time to recovery was extended, as DNS servers had to be rapidly reconfigured and BGP replicated across the internet, and multiple data centres powered up again. In Facebook’s case, this put an extensive strain on power systems.
Mistakes like these do and will always happen–so what’s the best way to mitigate them and minimize outages when they occur? You have two choices: passive or proactive.
1. Wait for customers to complain (or leave)
The Facebook outage caught front-page news because it affected so many individuals and businesses. For many smaller organisations, Facebook and Instagram are their primary digital connection with their customers, often because they’re cheaper and easier to maintain than a standard website, even if they have one. One example is the number of retailers and restaurants offering click-and-collect or delivery during lockdown via their Instagram accounts. Influencers–one of today’s growth businesses –would also have lost revenues.
In some countries, WhatsApp has become the de facto call and SMS service provider—even for government departments. Inability to access it (and its stored contact details) would have put many millions of people out of touch.
Further, Facebook is used for authentication for accessing other online services, making it the ‘digital front end’ for millions of other businesses. It is also the greatest connector of family and friends for the western world. While a single outage is unlikely to lose the behemoth a large swag of disciples, few digital platforms as resilient, especially where there are alternatives.
Overall, Facebook’s outage is variously estimated to have cost the company US$60-100 million in ad revenue and wiped US$40 billion off its market capitalisation. Other estimates reckon the outage could have cost the wider economy hundreds of millions each hour.
You are unlikely to have quite as many customers dependent on your digital services as Facebook, but such a catastrophic failure could cost your business considerable revenues. And worse, you could lose customers for good. Banking customers, for example, often operate accounts with multiple providers. If your service goes down, it could be the last straw that will see them walk.
2. Be proactive through early warning and diagnosis
Whether an outage is due to erroneous commands, as in these cases, or due to hacking, you need the tools to pinpoint the precise issues so you can fix them fast. As Facebook’s engineers reported, “All of this happened very fast. And as our engineers worked to figure out what was happening and why, they faced two large obstacles: first, it was not possible to access our data centers through our normal means because their networks were down, and second, the total loss of DNS broke many of the internal tools we’d normally use to investigate and resolve outages like this.”
Border gateway protocol (BGP), for example, can go down in just 90 seconds–or potentially sub-second, depending on how it’s deployed. Using Riverbed’s Unified Network Performance Monitoring platform of integrated online services, you can set synthetics at the packet level to post alarms if any changes occur. NetIM can monitor BGP passively, while AppResponse can look at packets to detect failure. This enables you to be on the front foot–before people complain.
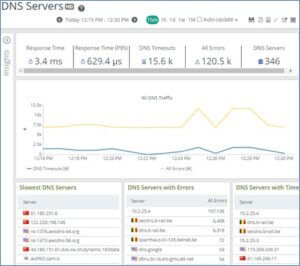
In the 11.12 release of AppResponse, we’ve introduced DNS Reporting and Alerting. AppResponse 11.12 includes brand new DNS analysis which previously required inspection using tools like SteelCentral Packet Analyzer or Wireshark. These new insights allow us to identify problems with DNS performance as well as compliance. This means that we can identify quickly, and accurately which clients are making what queries to which DNS servers, and if they are responded to.
The AppResponse DNS policies also allow us to identify when we see changes in our DNS traffic profiles. For example, we can alert on clients making connections to foreign DNS servers as an indicator of compromise. Another example could be increased DNS timeouts or errors.
These new features are included in AppResponse 11.12 and included if you are running the ASA feature license.
Stronger security makes it harder
As Facebook found, the strong security measures they have in place slowed their ability to bounce back up: “We’ve done extensive work hardening our systems to prevent unauthorized access, and it was interesting to see how that hardening slowed us down as we tried to recover from an outage caused not by malicious activity, but an error of our own making.”
As I wrote in my recent blog, Customer Experience Lessons from the Akamai Outage, major outages highlight the importance of redundancy for essential services like global load balancing. Moreover, they emphasise the need for end-to-end visibility to pinpoint any network, application or third-party service fault within minutes rather than hours. In today’s economy, digital customer experience and business continuity are what it’s all about.